TLNR#
The full text is about drawing the diagram below.
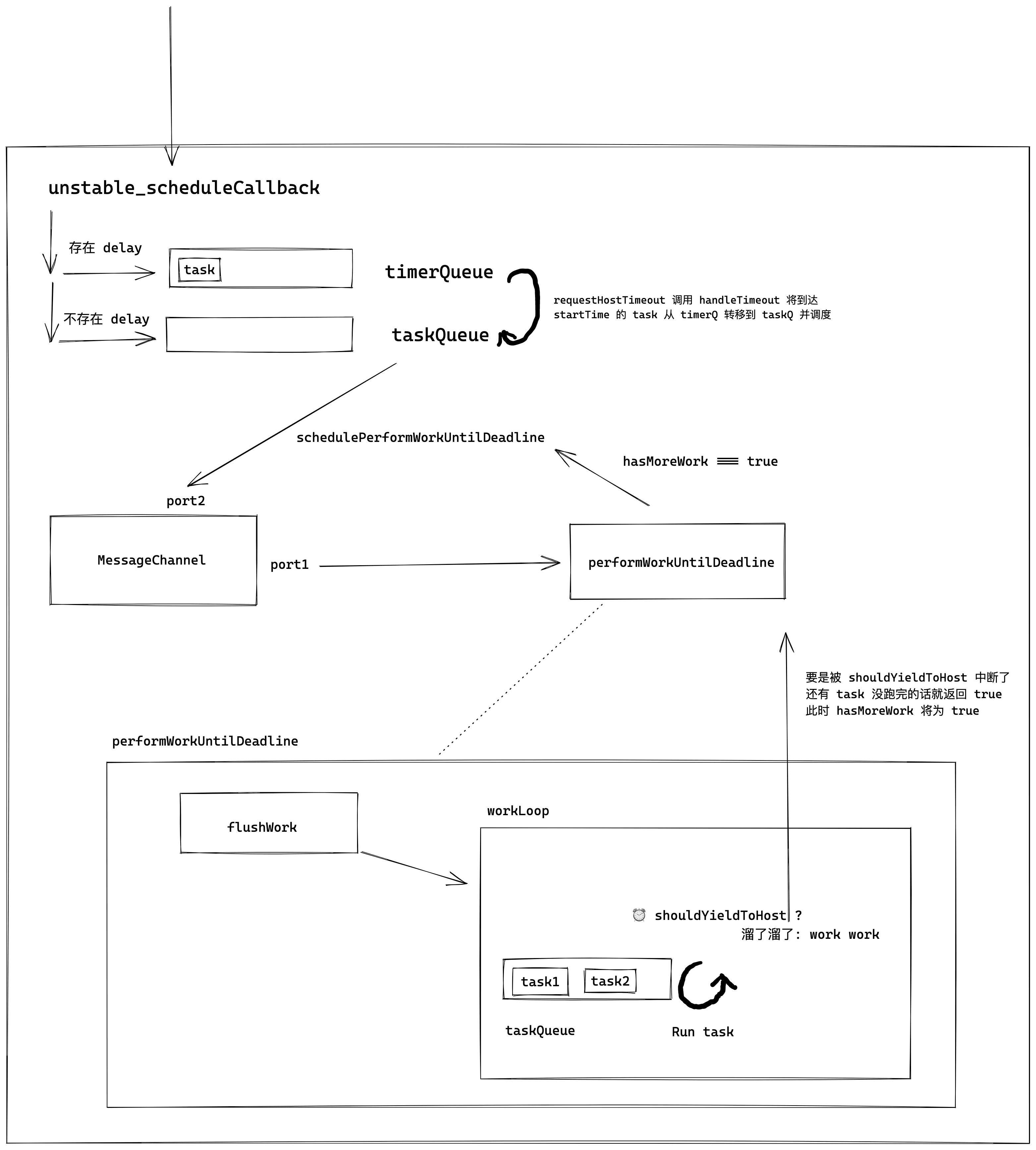
Description#
Scheduler, as the core of task scheduling in React, is an essential point for source code reading (the concept of time slicing actually exists within this package). Fortunately, this module is an independent package (it can be separated from some concepts within React, making the logic very clean), and after packaging, it has only about 700 lines, so the difficulty of reading is not too high.
There are two concepts within Scheduler, which I will mention here:
- Priority: Tasks generated within Scheduler will determine the execution order based on priority (the expiration time of the task), allowing high-priority tasks to be executed as quickly as possible.
- Time Slicing: The JS thread and the GUI thread are mutually exclusive, so if the JS task execution time is too long, it will block the rendering of the page, causing stuttering. Therefore, the concept of time slicing (usually 5ms) is introduced to limit the execution time of tasks. Once the time is exceeded, the currently executing task is interrupted, allowing the main thread to be given to the GUI thread to avoid stuttering.
Next, this article will start analyzing the source code from the unstable_scheduleCallback function, which can be seen as the entry function of Scheduler.
unstable_scheduleCallback#
Scheduler exposes this function to provide the ability to register tasks within Scheduler. When reading this function, the following points need to be noted:
- Scheduler generates task objects with different expiration times based on the passed priority level (priorityLevel).
- There are two arrays within Scheduler, timerQueue and taskQueue, used to manage tasks. The former manages tasks with delay > 0 (tasks that are not urgent to update), and the latter manages tasks with delay <= 0 (urgent tasks to update).
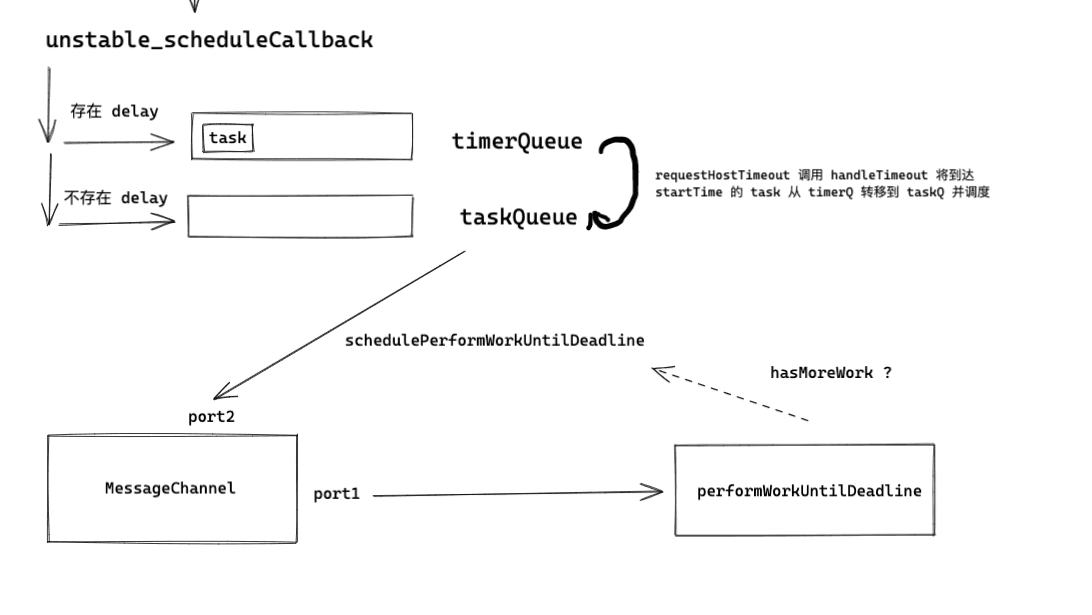
Based on the above logic, we can draw the following diagram.
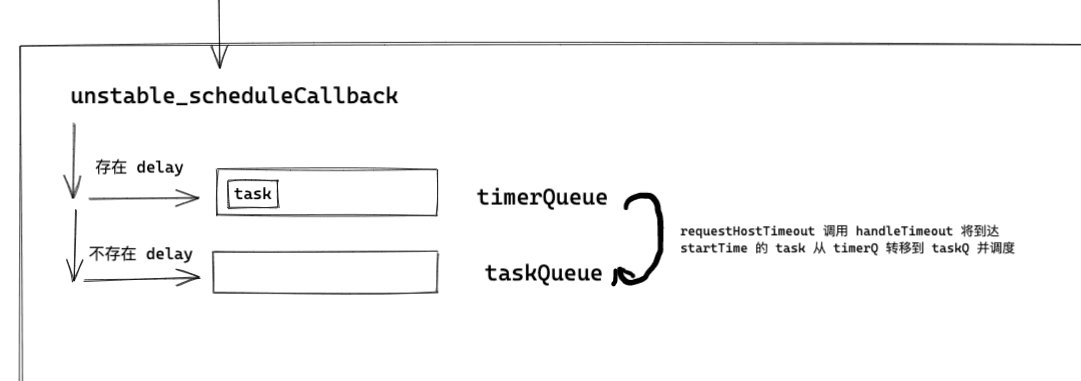
Next, let's take a brief look at what handleTimeout does.
The analysis of the entry-related parts has concluded. From the above code, it is not difficult to notice the code snippet requestHostCallback(flushWork), which will also become an entry point for analyzing scheduling behavior.
requestHostCallback#
requestHostCallback can be said to be an entry point for triggering scheduling behavior within Scheduler, so its analysis is also one of the key points in analyzing Scheduler. Next, let's look at its implementation.
From the above code snippet, it is not difficult to see that schedulePerformWorkUntilDeadline is its key function. However, its declaration distinguishes three scenarios:
- NodeJs environment, aimed at server-side rendering — setImmediate.
- Browser environment, aimed at web applications — MessageChannel.
- Compatibility environment — setTimeout.
However, this article only focuses on analyzing the browser environment, and here is its declaration.
MessageChannel can be looked up on MDN, but here I will emphasize one point: the asynchronous task type triggered by MessageChannel is MacroTask, so in most cases, after this task is executed, it will always trigger the browser's render.
From the above code, every time schedulePerformWorkUntilDeadline is called, it will trigger performWorkUntilDeadline. Now let's take a look at what this function does.
At this point, the schematic diagram of Scheduler has roughly been outlined.
Next, we need to complete the content of performWorkUntilDeadline. In the upcoming analysis, we will soon discuss the concept of time slicing.
flushWork and workLoop#
performWorkUntilDeadline will call scheduledHostCallback, and scheduledHostCallback is just an alias for flushWork (see requestHostCallback). However, flushWork only needs to focus on workLoop, which involves the core concepts of time slicing and interruption recovery.
After the above analysis, we can outline the general operations within performWorkUntilDeadline.
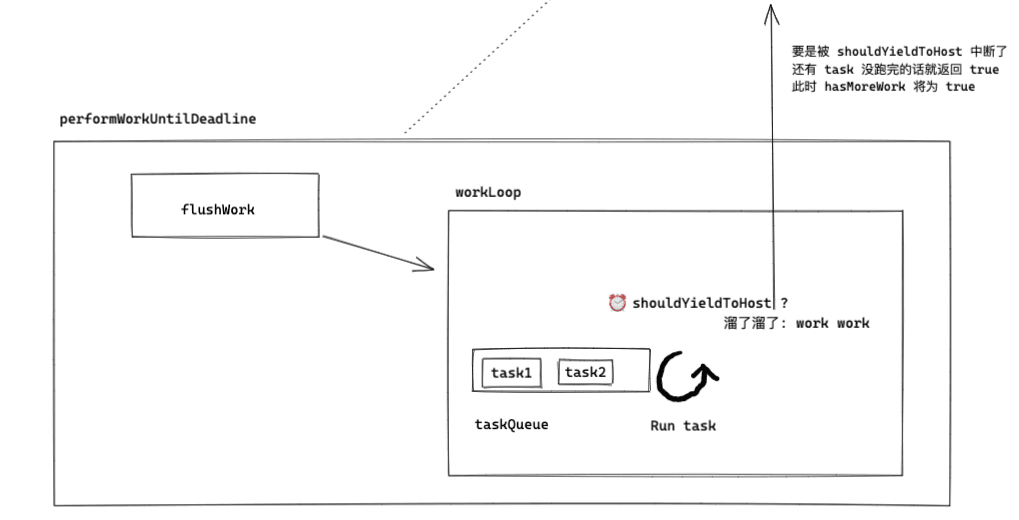
Next, let's see what this time slicing is all about.
Time slicing sounds impressive, but it is essentially the time taken for a single frame on the display. The reason for designing such a thing is quite simple: if the main thread of the rendering process is constantly occupied by the JS thread, and the GUI thread cannot intervene, then the page will not refresh continuously, leading to a drop in frame rate and causing the user to feel stutter. Therefore, once the execution time of a task exceeds the time slice, it is necessary to immediately interrupt the task to allow the browser to refresh the page.