TLNR#
The full text is about drawing the diagram below.
Description#
Scheduler, as the core of task scheduling in React, is an essential point for source code reading (the concept of time slicing actually exists within this package). Fortunately, this module is an independent package (it can be separated from some concepts within React, making the logic very clean), and after packaging, it has only about 700 lines, so the difficulty of reading is not too high.
There are two concepts within Scheduler, which I will mention here:
- Priority: Tasks generated within Scheduler will determine the execution order based on priority (the expiration time of the task), allowing high-priority tasks to be executed as quickly as possible.
- Time Slicing: The JS thread and the GUI thread are mutually exclusive, so if the JS task execution time is too long, it will block the rendering of the page, causing stuttering. Therefore, the concept of time slicing (usually 5ms) is introduced to limit the execution time of tasks. Once the time is exceeded, the currently executing task is interrupted, allowing the main thread to be given to the GUI thread to avoid stuttering.
Next, this article will start analyzing the source code from the unstable_scheduleCallback function, which can be seen as the entry function of Scheduler.
unstable_scheduleCallback#
Scheduler exposes this function to provide the ability to register tasks within Scheduler. When reading this function, the following points need to be noted:
- Scheduler generates task objects with different expiration times based on the passed priority level (priorityLevel).
- There are two arrays within Scheduler, timerQueue and taskQueue, used to manage tasks. The former manages tasks with delay > 0 (tasks that are not urgent to update), and the latter manages tasks with delay <= 0 (urgent tasks to update).
function unstable_scheduleCallback(priorityLevel, callback, options) {
/**
* Get the current time when the function runs, which will later be used to calculate the startTime of the task based on priority and to determine
* whether the task has expired.
* */
var currentTime = exports.unstable_now();
var startTime;
/**
* The external may manually pass in delay to postpone the execution of the task.
*/
if (typeof options === 'object' && options !== null) {
var delay = options.delay;
if (typeof delay === 'number' && delay > 0) {
startTime = currentTime + delay;
} else {
startTime = currentTime;
}
} else {
startTime = currentTime;
}
var timeout;
/**
* The timeout will be assigned different values based on the priority level.
* The timeout corresponding to ImmediatePriority is -1, so tasks of this priority can be considered expired upon registration,
* and will be executed quickly.
*/
switch (priorityLevel) {
case ImmediatePriority:
timeout = IMMEDIATE_PRIORITY_TIMEOUT; // -1
break;
case UserBlockingPriority:
timeout = USER_BLOCKING_PRIORITY_TIMEOUT; // 250
break;
case IdlePriority:
timeout = IDLE_PRIORITY_TIMEOUT; // 1073741823
break;
case LowPriority:
timeout = LOW_PRIORITY_TIMEOUT; // 10000
break;
case NormalPriority:
default:
timeout = NORMAL_PRIORITY_TIMEOUT; // 5000
break;
}
/**
* Calculate the expiration time.
*/
var expirationTime = startTime + timeout;
var newTask = {
id: taskIdCounter++,
callback: callback, // The function registered for the task
priorityLevel: priorityLevel,
startTime: startTime, // Task start time
expirationTime: expirationTime, // Expiration time
sortIndex: -1 // Basis for min-heap sorting
};
if (startTime > currentTime) {
// This is a delayed task. Because a delay is set, this is a task that needs to set a timer.
newTask.sortIndex = startTime;
// Push this task into the timerQueue.
push(timerQueue, newTask);
if (peek(taskQueue) === null && newTask === peek(timerQueue)) {
// All tasks are delayed, and this is the task with the earliest delay.
// taskQueue is empty, and the current task is the first in timerQueue.
if (isHostTimeoutScheduled) {
// Cancel an existing timeout.
cancelHostTimeout();
} else {
isHostTimeoutScheduled = true;
} // Schedule a timeout.
// requestHostTimeout is just a wrapped timer.
/**
* handleTimeout is a function that starts scheduling, which will be analyzed later.
* In this code, it can be temporarily understood as starting scheduling to execute the current task.
* */
requestHostTimeout(handleTimeout, startTime - currentTime);
}
} else {
/**
* If no delay is set, directly push the task into taskQueue.
*/
newTask.sortIndex = expirationTime;
push(taskQueue, newTask);
// Wait until the next time we yield.
if (!isHostCallbackScheduled && !isPerformingWork) {
isHostCallbackScheduled = true;
/**
* flushWork is a relatively important function that involves clearing the taskQueue.
* requestHostCallback will trigger MessageChannel to execute performWorkUntilDeadline, which will be analyzed in detail later.
* Here, the following code can be understood as calling flushWork to clear the tasks in taskQueue.
*/
requestHostCallback(flushWork);
}
}
return newTask;
}
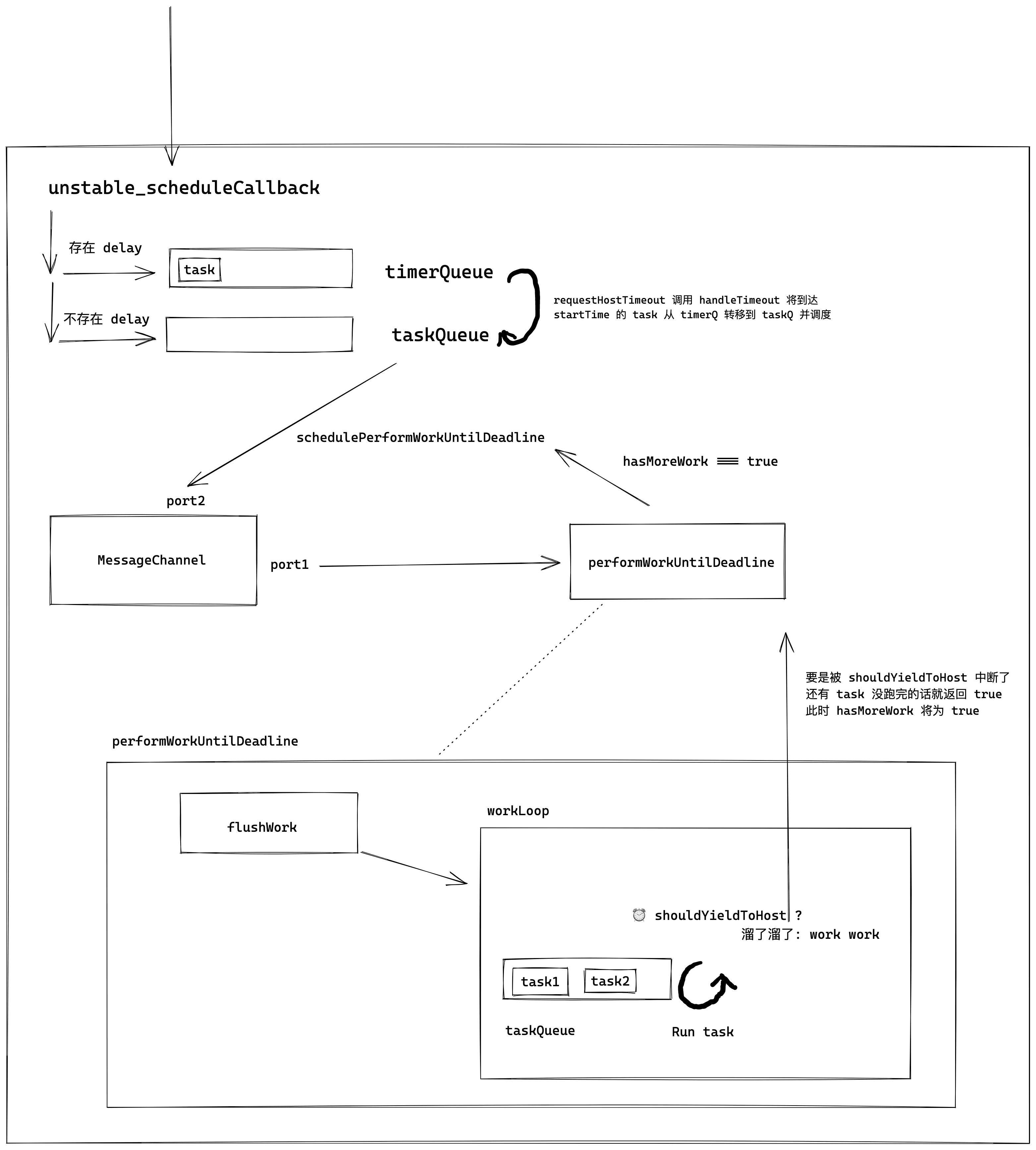
Based on the above logic, we can draw the following diagram.
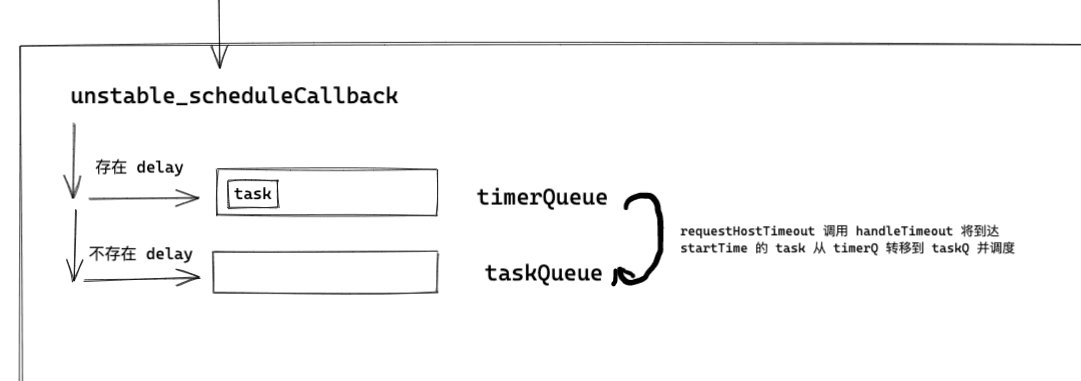
Next, let's take a brief look at what handleTimeout does.
/**
* After advanceTimers organizes timerQ and taskQ,
* if there are tasks in taskQ, schedule that task.
* Otherwise, check if there are tasks in timerQ; if so, set a timer to its startTime and call handleTimeout.
*/
function handleTimeout(currentTime) {
isHostTimeoutScheduled = false;
advanceTimers(currentTime); // Function to organize timerQ and taskQ, see analysis below.
if (!isHostCallbackScheduled) {
if (peek(taskQueue) !== null) {
/**
* When taskQ is not empty, start scheduling.
*/
isHostCallbackScheduled = true;
// The same operation exists in unstable_scheduleCallback, which is the entry point for starting scheduling.
requestHostCallback(flushWork);
} else {
/**
* At this point, there are no tasks in taskQ to schedule.
* We can only check if there are tasks in timerQ that have reached startTime.
*/
var firstTimer = peek(timerQueue);
if (firstTimer !== null) {
/**
* Set a timer for the first element in timerQ to wait for it to reach startTime,
* then use advanceTimers to transfer the task to taskQ and schedule it.
*/
requestHostTimeout(handleTimeout, firstTimer.startTime - currentTime);
}
}
}
}
/**
* Continuously traverse timerQ to take out tasks that have reached startTime and put them into taskQ.
* Additionally, it is responsible for discarding canceled tasks.
*/
function advanceTimers(currentTime) {
// Check for tasks that are no longer delayed and add them to the queue.
var timer = peek(timerQueue);
while (timer !== null) {
if (timer.callback === null) { // unstable_cancelCallback cancels the task by setting its callback to null.
// Timer was cancelled.
pop(timerQueue); // Here, the canceled task is discarded.
} else if (timer.startTime <= currentTime) {
// Timer fired. Transfer to the task queue.
// The task has reached startTime, move it to taskQ.
pop(timerQueue);
timer.sortIndex = timer.expirationTime;
push(taskQueue, timer);
} else {
// Remaining timers are pending.
return;
}
timer = peek(timerQueue);
}
}
The analysis of the entry-related parts has concluded. From the above code, it is not difficult to notice the code snippet requestHostCallback(flushWork), which will also become an entry point for analyzing scheduling behavior.
requestHostCallback#
requestHostCallback can be said to be an entry point for triggering scheduling behavior within Scheduler, so its analysis is also one of the key points in analyzing Scheduler. Next, let's look at its implementation.
/**
* Based on requestHostCallback(flushWork)
* Here, the callback is flushWork.
*/
function requestHostCallback(callback) {
scheduledHostCallback = callback; // Assign flushWork to scheduledHostCallback.
if (!isMessageLoopRunning) {
isMessageLoopRunning = true;
schedulePerformWorkUntilDeadline(); // Key function.
}
}
From the above code snippet, it is not difficult to see that schedulePerformWorkUntilDeadline is its key function. However, its declaration distinguishes three scenarios:
- NodeJs environment, aimed at server-side rendering — setImmediate.
- Browser environment, aimed at web applications — MessageChannel.
- Compatibility environment — setTimeout.
However, this article only focuses on analyzing the browser environment, and here is its declaration.
var channel = new MessageChannel();
var port = channel.port2;
channel.port1.onmessage = performWorkUntilDeadline;
schedulePerformWorkUntilDeadline = function () {
port.postMessage(null);
};
MessageChannel can be looked up on MDN, but here I will emphasize one point: the asynchronous task type triggered by MessageChannel is MacroTask, so in most cases, after this task is executed, it will always trigger the browser's render.
From the above code, every time schedulePerformWorkUntilDeadline is called, it will trigger performWorkUntilDeadline. Now let's take a look at what this function does.
var performWorkUntilDeadline = function () {
/**
* Here, scheduledHostCallback is actually flushWork.
* See requestHostCallback for details.
*/
if (scheduledHostCallback !== null) {
var currentTime = exports.unstable_now();
startTime = currentTime;
var hasTimeRemaining = true;
var hasMoreWork = true;
try {
/**
* Execute flushWork, its return value indicates whether taskQ is empty.
* If not empty, it means there are still tasks to be scheduled.
*/
hasMoreWork = scheduledHostCallback(hasTimeRemaining, currentTime);
} finally {
/**
* If there is more work,
*/
if (hasMoreWork) {
// If there's more work, schedule the next message event at the end
// of the preceding one.
/**
* Because there are still tasks to schedule, trigger MessageChannel again.
*/
schedulePerformWorkUntilDeadline();
} else {
isMessageLoopRunning = false;
scheduledHostCallback = null;
}
}
} else {
isMessageLoopRunning = false;
} // Yielding to the browser will give it a chance to paint, so we can
};
At this point, the schematic diagram of Scheduler has roughly been outlined.
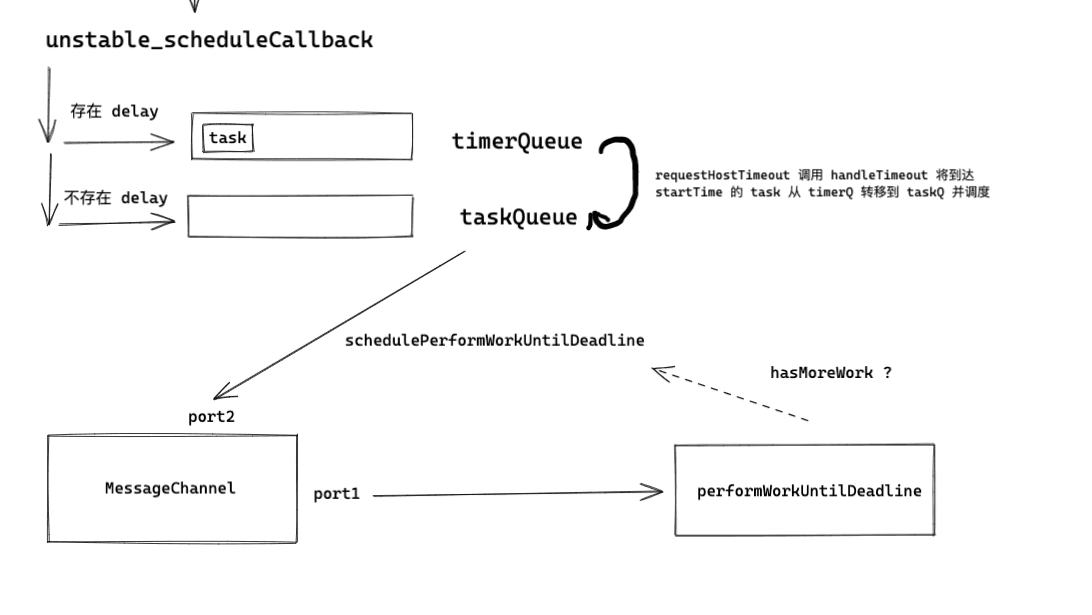
Next, we need to complete the content of performWorkUntilDeadline. In the upcoming analysis, we will soon discuss the concept of time slicing.
flushWork and workLoop#
performWorkUntilDeadline will call scheduledHostCallback, and scheduledHostCallback is just an alias for flushWork (see requestHostCallback). However, flushWork only needs to focus on workLoop, which involves the core concepts of time slicing and interruption recovery.
/**
* Its purpose is simply to call workLoop.
*/
function flushWork(hasTimeRemaining, initialTime) {
/**
* hasTimeRemaining is assigned true.
* initialTime is the timestamp when performWorkUntilDeadline is called.
*/
isHostCallbackScheduled = false;
if (isHostTimeoutScheduled) {
// We scheduled a timeout but it's no longer needed. Cancel it.
/**
* Prioritize clearing taskQ to prevent the contents set by the timer from jumping the queue.
* Cancel any existing timers.
*/
isHostTimeoutScheduled = false;
cancelHostTimeout();
}
isPerformingWork = true;
var previousPriorityLevel = currentPriorityLevel;
try {
if (enableProfiling) {
try {
/**
* The focus of the entire flushWork is actually to call workLoop.
*/
return workLoop(hasTimeRemaining, initialTime);
} catch (error) {
if (currentTask !== null) {
var currentTime = exports.unstable_now();
markTaskErrored(currentTask, currentTime);
currentTask.isQueued = false;
}
throw error;
}
} else {
// No catch in prod code path.
return workLoop(hasTimeRemaining, initialTime);
}
} finally {
currentTask = null;
currentPriorityLevel = previousPriorityLevel;
isPerformingWork = false;
}
}
/**
* Loop through taskQ and execute the callback of each task.
*/
function workLoop(hasTimeRemaining, initialTime) {
var currentTime = initialTime;
/**
* Organize timerQ and taskQ.
*/
advanceTimers(currentTime);
currentTask = peek(taskQueue); // Get the first task.
while (currentTask !== null && !(enableSchedulerDebugging)) {
/**
* If the task has expired and the time slice has not been used up, continue the while loop; otherwise, break.
* The content of shouldYieldToHost contains the time slicing, which will be analyzed separately later.
*/
if (currentTask.expirationTime > currentTime && (!hasTimeRemaining || shouldYieldToHost())) {
// This currentTask hasn't expired, and we've reached the deadline.
break;
}
var callback = currentTask.callback;
/**
* The callback can be either function/null.
* If it's a function, it's a valid task.
* If it's null, it's a canceled task.
*/
if (typeof callback === 'function') {
currentTask.callback = null;
currentPriorityLevel = currentTask.priorityLevel;
var didUserCallbackTimeout = currentTask.expirationTime <= currentTime;
/**
* If you use Performance tools to record here,
* it is not difficult to find that the callback here is actually performConcurrentWorkOnRoot,
* and in that function, when root.callbackNode === originalCallbackNode is satisfied,
* it means the original task has not been completed, and it will return to performConcurrentWorkOnRoot itself to resume the interrupted task.
*
* To add, the reason why there may be interruptions here is mainly because the time slice has run out, which is the content of shouldYieldToHost().
*
* Tip: Don't get too caught up in the details; the biggest pitfall in reading source code is getting lost in the details (I will supplement this debugging record later when I have time).
*/
var continuationCallback = callback(didUserCallbackTimeout);
currentTime = exports.unstable_now();
if (typeof continuationCallback === 'function') {
/**
* Because it hasn't finished executing, reassign the task's callback so that it can resume the interrupted task on the next call.
*/
currentTask.callback = continuationCallback;
} else {
/**
* Here, the task has successfully completed, so we can discard this task.
*/
if (currentTask === peek(taskQueue)) {
pop(taskQueue);
}
}
/**
* After analysis, if you forget to scroll up...
*/
advanceTimers(currentTime);
} else {
/**
* Because it is a canceled task,
* there is no need to execute it, so pop it off.
*/
pop(taskQueue);
}
currentTask = peek(taskQueue);
} // Return whether there's additional work.
/**
* Even if the while loop is interrupted due to the time slice running out, it will still enter the following judgment logic.
*/
if (currentTask !== null) {
// If it was interrupted due to the while loop, then currentTask must not be null.
// Thus, return true.
return true;
} else {
// If the while loop ends, then currentTask must be null.
var firstTimer = peek(timerQueue);
if (firstTimer !== null) {
// As long as timerQueue is not empty, start the next round of scheduling.
requestHostTimeout(handleTimeout, firstTimer.startTime - currentTime);
}
// Since the task has completed, there are no remaining tasks, so return false.
return false;
}
// The return value of workLoop is actually assigned to hasMoreWork.
}
After the above analysis, we can outline the general operations within performWorkUntilDeadline.
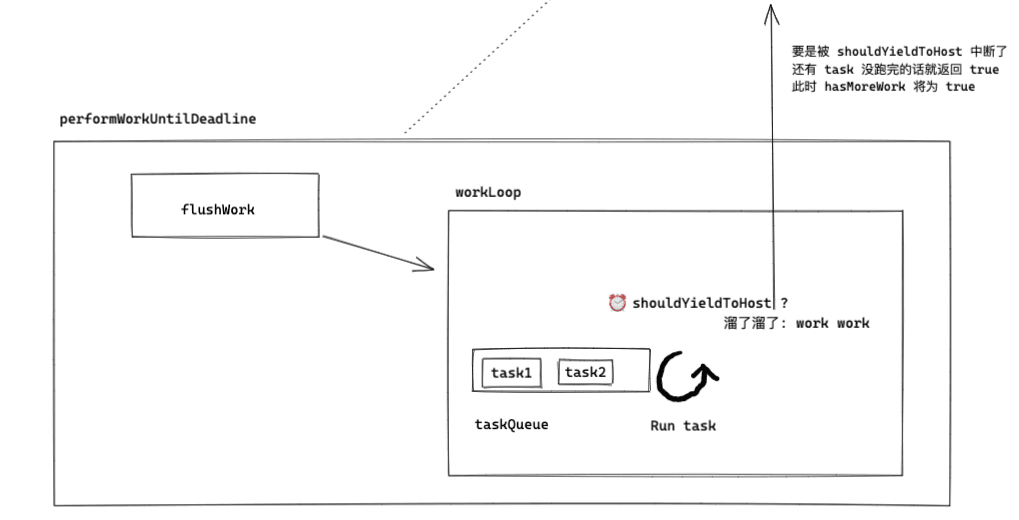
Next, let's see what this time slicing is all about.
function shouldYieldToHost() {
/**
* performWorkUntilDeadline assigns startTime at the beginning of execution.
*/
const timeElapsed = getCurrentTime() - startTime;
/**
* frameInterval's default value is 5 ms,
* but it will also be automatically calculated based on the monitor's fps (0, 125),
* calculated as Math.floor(1000 / fps).
* This means the duration of a single frame, and this value is the time slice.
*/
if (timeElapsed < frameInterval) {
// The main thread has only been blocked for a really short amount of time;
// smaller than a single frame. Don't yield yet.
// Because there's still plenty of time, no need to interrupt.
return false;
}
// The main thread has been blocked for a non-negligible amount of time. We
// may want to yield control of the main thread, so the browser can perform
// high priority tasks. The main ones are painting and user input. If there's
// a pending paint or a pending input, then we should yield. But if there's
// neither, then we can yield less often while remaining responsive. We'll
// eventually yield regardless, since there could be a pending paint that
// wasn't accompanied by a call to `requestPaint`, or other main thread tasks
// like network events.
/**
* In short: we prioritize responding to user input, balabala.
*/
if (enableIsInputPending) {
if (needsPaint) {
// There's a pending paint (signaled by `requestPaint`). Yield now.
return true;
}
if (timeElapsed < continuousInputInterval) {
// We haven't blocked the thread for that long. Only yield if there's a
// pending discrete input (e.g. click). It's OK if there's pending
// continuous input (e.g. mouseover).
if (isInputPending !== null) {
return isInputPending();
}
} else if (timeElapsed < maxInterval) {
// Yield if there's either a pending discrete or continuous input.
if (isInputPending !== null) {
return isInputPending(continuousOptions);
}
} else {
// We've blocked the thread for a long time. Even if there's no pending
// input, there may be some other scheduled work that we don't know about,
// like a network event. Yield now.
return true;
}
}
// `isInputPending` isn't available. Yield now.
// If isInputPending is not available, then yield.
return true;
}
Time slicing sounds impressive, but it is essentially the time taken for a single frame on the display. The reason for designing such a thing is quite simple: if the main thread of the rendering process is constantly occupied by the JS thread, and the GUI thread cannot intervene, then the page will not refresh continuously, leading to a drop in frame rate and causing the user to feel stutter. Therefore, once the execution time of a task exceeds the time slice, it is necessary to immediately interrupt the task to allow the browser to refresh the page.